基于灰度的共生矩阵法的人脸表情识别探究
时间:2018-12-12 09:25:03点击:886次
人脸表情是人类进行情感交流的一种重要方式,从表情的变化中可以感知出人的情绪、感受、秉性和气质。自动化的人脸表情识别(FER)技术可以协助进行人脸识别、智能人机交互以及行为科学和医学研究等。根据所研究数据的不同, FER 算法可以分为针对多幅图像和针对单幅图像两大类。由于单幅图像包含较少的表情信息, 从单幅图像识别表情比从多幅图像中进行更具挑战性。然而, 在有些情况下, 单幅图像中已包含了足够的表情信息, 而且计算相对简单。因此,本文主要探讨基于单幅图像的人脸表情识别。
人脸表情识别主要分为三个步骤:寻找感兴趣区域(ROI)、特征提取和表情图像分类。寻找感兴趣区域,目前常用的方法有基于模板匹配的方法和基于特征提取的方法,前者考虑图像全局;后者则考虑图像局部区域,主要考虑形状和纹理。通过特征提取过程降低维数,目前常用的方法有主成分分析(PCA)、Gabor过滤等方法。通过对从ROI中提取出来的特征向量进行分类,目前常用的方法有神经网络(NN)、隐式马尔可夫链(HMM)和支持向量机(SVM)。上述基本方法使研究仅仅考虑到如何在各个步骤中优化算法,忽略了步骤之间的依赖性,因为先要选定ROI,然后再进行特征提取,所以步骤连接中需要人工干预。针对此问题,本文有效地利用CGA,通过CGA的不断迭代将前两步有机结合,实现了自动机制,并且简化了设计。
最近,HERNANDEZ B等人提出利用灰度共生矩阵和遗传算法相结合的方法解决红外线图像上的人脸表情识别问题,其中存在一些不足之处:遗传算法中个体是随机产生的,造成个体在空间内分布的不均匀性,使得实验效果并不明显;仅可解决红外线图像。针对以上不足,本文首先将灰度共生矩阵拓展到可视化图像上,并用相应的实验数据证明其可行性。利用混沌的随机性、遍历性和规律性,将混沌原理加入遗传算法中,对传统遗传算法进行改进,有效地解决了个体分布的不均匀性,同时也没有忽略其差异性。经过理论推导和实验仿真,证明本文的方法是切实可行的。
1 灰度共生矩阵(GLCM)
纹理是图像分析中常用的特征,一般说来可以认为纹理由许多相互接近的、互相交织的元素组成,并具有一定的周期性。量化图像的纹理内容是描述图像的一种重要方法。基于统计的方法是纹理分析中最基本的一类方法,而基于灰度的共生矩阵法又是一种典型有效的基于统计的纹理提取方法。因此,本文选取灰度共生矩阵来提取特征。


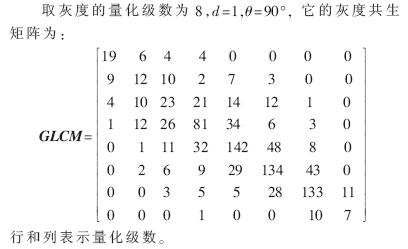
这样得到的矩阵可以反映不同像素相对位置的空间信息。共生矩阵中还包含了图像的纹理信息,对于具有不同特点的图像纹理,其灰度共生矩阵也会明显不同。对纹理较为粗糙的区域,其灰度共生矩阵中mij的值较集中于主对角线附近,对于粗糙纹理,像素对一般具有相同的灰度;而对于纹理较为细腻的区域,其灰度共生矩阵中mij的值则散布在各处,其像素对灰度差异较大。
1.2 GLCM用于表情识别的可行性分析
1978年,EKMAN和FRIESEN提出了面部表情编码系统(FACS),并研究了六种基本表情,即高兴、悲伤、惊讶、恐惧、愤怒和厌恶。
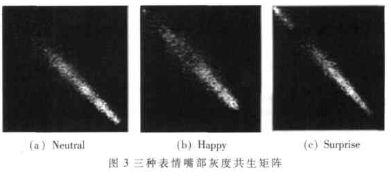
表情变化的区域主要集中在眼睛、眉毛和嘴巴,因此,采用公式(1)选取JAFFE 图库中“Neutral”、“Happy”、“Surprise”三种表情对三个主要集中区域之一的嘴部区域进行实验,如图2所示。

由以上三种表情嘴部区域所生成的灰度共生矩阵如图3所示。由图3可以看出,对于“Happy”这种表情来说,其嘴部区域的灰度值比之另外两种表情的嘴部区域变化要频繁,其图像的纹理特性相对属于“细纹理”。而另两种属于“粗纹理”,其灰度共生矩阵中的值较集中于主对角线附近。对于粗纹理,像素对趋于具有相同的灰度;而对于细纹理的区域,其灰度共生矩阵中的值则散布在各处。就“Neutral”与“Surprise”这两种表情而言,“Neutral”表情的嘴部区域口形较小,因为嘴附近肤色的缘故,其灰度值多处于高亮度区域,反映在灰度共生矩阵上则是主对角线上小序号行列的数值较低,连通性较差。而“Surprise”表情的嘴部区域口形较大,其灰度值多处于低亮度区域,因而其灰度共生矩阵主对角线上数值比较均衡,连通性较好。
由此可见,用灰度共生矩阵可以反应出各种表情之间的差异,不难想象从中提取出的各种统计量就可以作为表情特性的度量。
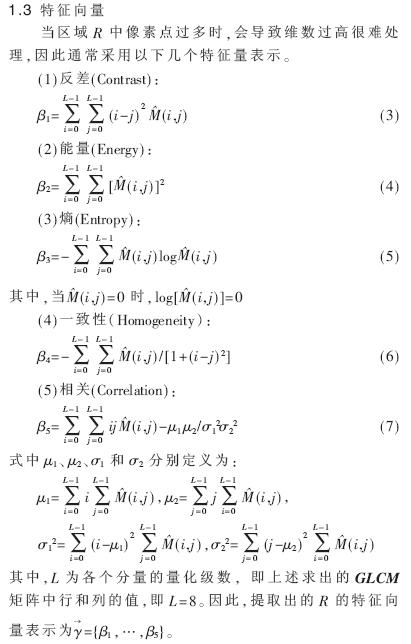
2 支持向量机(SVM)
支持向量机(SVM)起初由VAPNIK提出时,是作为寻求最优(在一定程度上)二分类器的一种技术,后来它又被拓展到回归和聚类应用。
2.1 SVM定义
定义2 SVM是一种基于核函数的方法,它通过某些核函数把特征向量映射到高维空间,然后建立一个线性判别函数(或者说是一个高维空间中的能够区分训练数据的最优超平面)。解是最优的在某种意义上是两类中

2.2 SVM多分类方法
SVM算法最初是为二值分类问题设计的,当处理多类问题时,就需要构造合适的多类分类器。目前,构造SVM多类分类器的方法主要有两类:一类是直接法,直接在目标函数上进行修改,将多个分类面的参数求解合并到一个最优化问题中,通过求解该最优化问题“一次性”实现多类分类,这种方法看似简单,但其计算复杂度比较高,实现起来比较困难,只适用于小型问题中;另一类是间接法,主要是通过组合多个二分类器来实现多分类器的构造常见的方法有两种。(1)一对多法(one-versus-rest)。训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。分类时将未知样本分类为具有最大分类函数值的那类。(2)一对一法(one-versus-one)。其做法是在任意两类样本之间设计一个SVM,因此k个类别的样本就需要设计k(k-1)/2个SVM。当对一个未知样本进行分类时,得票最多的类别即为该未知样本的类别。除了以上两种方法外,还有有向无环图DAG(Directed Acyclic Graph)和对类别进行二进制编码的纠错编码(Error Correcting Code)。本文采用第二种方法并结合投票策略(voting scheme)[5]来设计需要的多分类器。
2.3 k-折交叉验证(K-fold cross-validation)
由于我们的数据样本集较小,因此引入k-折交叉验证。
定义3 k-折交叉验证是指将样本集分为k份,其中k-1份作为训练数据集,而另外的1份作为验证数据集。用验证集来验证所得分类器或者回归的错误码率。一般需要循环k次,直到所有k份数据全部被选择一遍为止。
3 混沌遗传优化算法(CGA)
3.1 遗传算法的改进
遗传算法是一种模拟生物进化过程的优化方法,它能在有限代数的进化过程中,在全局解空间内自动进行搜索得到最优解或是次优解。它可以通过编码技术,将具体的问题抽象处理,仅对编码串进行操作,在进化过程中以适应度作为标准,从而避开了问题的复杂优化判别准则。但是遗传算法对初始种群最初是采用一种随机方式产生的,这些个体在解空间内分布可能不均匀,为了使遗传算法能在解空间内更好地进行全局搜索, 杨宇明等人[6]提出一种新的随机个体产生方法,将混沌原理引入遗传算法。混沌具有随机性、遍历性和规律性,用它产生初始种群会提高遗传算法的效率,使遗传算法的初始种群不再随机产生,而是由混沌产生。混沌是一种非线性的映射,它看似随机的过程,其实质是一种有着内在机制的运动过程。因此,本文也将混沌原理引入,对遗传算法进行改进,采用logostic映射表示混沌的系统:
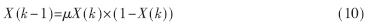
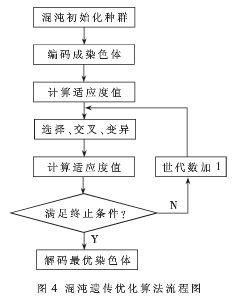
当μ=4时,这个系统是一个完全混沌系统,它没有稳定解,而且是一个满映射的过程。这些特性能够提高遗传算法初始种群的差异性。混沌遗传优化算法过程[7]如图4所示。
3.2 适应度函数(Fitness function)
GA应用于实际问题时,适应度函数的定义往往最为困难,而且其计算复杂程度对于整个GA的搜索时间有较大影响。本文方法的目标就是寻找最佳的ROI,在ROI上面提取特征用于分类。因此,每个选定的ROI分类的正确性对适应度函数起至关重要的作用。然而,当两个不同的解决方法得到同样的分类正确性时,为了简化计算应该选择特征值数量较少者,因此,本文适应度函数[8]设计如下:
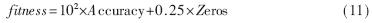
其中,Accuracy为对于给定个体所有SVM的平均正确率,可由k-折交叉验证[5]求得;Zeros为染色体中起作用的特征值数量。
3.3 选择、交叉和变异
选择方法:假设群体规模为N,经交叉、变异操作后产生N个子代个体。将子父代组成的2N个群体按适应度函数值从大到小排序,取前面N/2个个体放入配对池,再从后面的N个个体中随机地选出N/2个个体放入配对池。由于既选择到适应度函数的较大值又选择到适应度函数的较小值,这样,既可保证种群向最优解收敛,又可保证种群的多样性不会迅速减少。
变异算子选择:为了简化实验,提高实验性能,本文采用基本位变异作为变异算子,即以变异概率对个体编码串中基因座上的基因值做变异运算。
交叉算子选择:同样为了简化实验提高实验性能,本文的交叉算子采用单点杂交算子[10],在个体编码串中随机设置一个杂交点,然后进行部分基因变换。

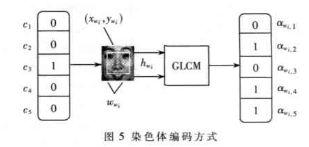


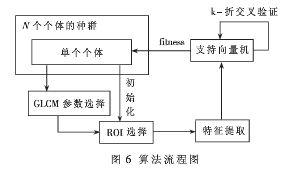
5 实验结果及分析
本文选用Matlab 7.0为实验平台,从JAFFE图库中选出“Happy”、“Neutral” 、“Angry”和“Surprise”四种表情的图像样本共121幅,其中:“Happy”表情31幅、“Neutral”表情30幅、“Angry”表情30幅、“Surprise”表情30幅。从这些图像样本中选择“Happy”表情16幅、“Neutral”表情15幅、“Angry”表情15幅、“Surprise”表情15幅共61幅作为训练样本,剩余每种表情15幅,共60幅作为测试样本。经过实验选定种群大小为50,最大遗传代数为50,经过三次实验,求得的识别率如表1所示。
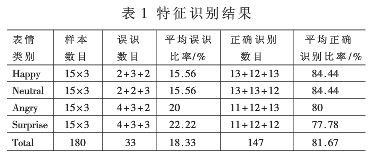
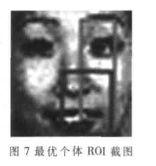
由表1不难得出,采用灰度共生矩阵特征值表征的特征对“Happy”和“Neutral”识别效果较为理想,对于“Angry”也有较高的识别率,对“Surprise”识别率较低。总体来说,本文提出的基于灰度共生矩阵和混沌遗传优化算法相结合的算法能够得到81.67%的平均识别率,识别结果令人满意。最优个体的感兴趣区域数目为2,参数为{14 16 13 15}和{19 3 9 25},分别对应中心点坐标(xwi,ywi)、ROI宽度hwi和ROI高度wwi。最优个体ROI在JAFFE库上一个实例的区域截图如图7所示。
本文提出了利用CGA将ROI的选取和特征的提取有机地结合,通过不断调整灰度共生矩阵的参数寻找最优个体,利用最优个体标明的ROI训练SVM,最后通过SVM进行分类。该方法的优点在于能够很好地利用人脸表情处理步骤之间的依赖性,将前两个步骤有机地结合成一步,消除了步骤连接中的人为因素,实现了自动机制,并且简化了设计,而且将混沌原理引入遗传算法当中,有效地解决了随机产生个体的不均匀性,又保持了个体的差异性。通过定理、公式推导和实验仿真,证明该方法切实可行。